[ROI 2019] 考古 (Day 2)
Background
Translated from ROI 2019 D2T4。
In the year 3019, while excavating the ancient city of Innopolis, archaeologists discovered an ancient artifact—a hard drive. It contained a file which is believed to include the texts of all ROI problems.
After studying the file, it was found that the information was encoded as a string consisting of English letters. The problem texts are very long and contain many repeated parts, so the file was stored on the hard drive in compressed form. The file is decompressed using the following algorithm:
During decompression, a string consisting of lowercase English letters will be produced. Initially, the string is empty. The compressed file contains blocks, and you must process each block in order. Each block is of one of the following two types.
- Block
1 w, where is a string. When processing such a block, append the string to the end of . - Block
2 pos len, where and are positive integers. Assume that the characters of are numbered starting from . When processing such a block, append to the end of the consecutive characters starting from position in , in order. If is large enough, some of the characters that were just appended may be used again while processing the same block.
Problem Description
The archaeologists decided to count how many times an algorithm was tested in ROI. For this, they constructed a string consisting of lowercase English letters, and they want to find the number of occurrences of this string in the decompressed string .
A string of length occurs as a substring starting at position if the consecutive characters starting from the -th character equal . For example, the string aba occurs three times as a substring in the string ababaaba, starting at characters .
Write a program to determine the number of occurrences of the given string in the decompressed string .
Input Format
The first line contains two non-negative integers and , representing the length of the string and the number of blocks in the compressed text, respectively.
The second line contains a non-empty string , consisting of lowercase English letters.
The next lines contain the descriptions of the blocks in the format given in the Background section.
Output Format
Output one integer: the number of occurrences of the string in the text.
3 4
aba
1 ab
2 1 3
2 3 3
2 1 8
6
Hint
Sample Explanation:
The decompression process of is as follows:
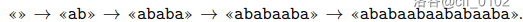
aba occurs times in ababaabaababaaba.
Constraints:
Let the length of the string after decompressing the first blocks be , and let the type of the -th block be .
| Subtask | Points | Other Special Properties | |||
|---|---|---|---|---|---|
contains only the letter a, |
|||||
contains only the letter a |
|||||
For of the testdata, 。
Translated by ChatGPT 5